
Đoàn Việt Hà1, Trần Danh Cường1,2, Nguyễn Thị Trang1, Ngô Toàn Anh2, Lương Thị Lan Anh1, Tô Thị Thu Hà1, Nguyễn Thị Huệ1, Nguyễn Phương Ngọc1, Đỗ Đức Huy1, Nguyễn Thị Khánh2, Đặng Phương Thuý2, Nguyễn Thị Thu Hương2, Lê Phạm Sỹ Cường2, Lê Dương Minh Anh1, Phạm Hùng Sơn1, Hoàng Thị Ngọc Lan1, Đoàn Kim Phượng1, Vũ Thị Huyền1, Vũ Thị Hà1, Phạm Quang Anh, Nguyễn Hữu Đức Anh1
1Đại học Y Hà Nội
2Bệnh viện Phụ sản Trung ương
3Đại học Y Thái Bình
Chịu trách nhiệm chính: Nguyễn Thị Trang
Email: trangnguyen@hmu.edu.vn
Ngày nhận bài: 16/7/2022
Ngày phản biện khoa học: 02/08/2022
Ngày duyệt bài: 21/08/2022
TÓM TẮT
SUMMARY
APPLYING A MACHINE LEARNING SOFTWARE IN PRENATAL SCREENING FOR COMMON CONGENITAL ABNORMALITIES (DOWN, EDWARDS, AND PATAU SYNDROME) IN VIETNAM
Objectives: (1) Calculating regression equations for Vietnamese-specific median value of maternal serum markers in prenatal screening adjusted for gestational age and maternal weight, (2) Building and assessing the efficiency of a machine learning software in prenatal screening for Down, Edwards, and Patau syndrome in Vietnam. Subjects and methods: A meta-analytic study, prospective and retrospective data collection on 10,181 pregnant women at the National Hospital of Obstetrics and Gynecology from January 2012 to March 2022. Results: Regression equations for median values of free β-hCG, PAPP-A, uE3, AFP, and hCG by gestational age (in days) are in the form: f(x)= P1×X2 +P2×X+P3, and MoM correction equations for maternal weight have high R2 values (all greater than 0.5). We successfully built a machine learning software. When using a dataset combining markers and ultrasound results, the XGBoost model has the highest accuracy (98.1% for Down syndrome and 97.5% for Edwards and Patau syndrome). Conclusion: The XGBoost-based AI software could be applied in prenatal screening for Down, Edwards, and Patau syndrome.
Keywords: Artificial Intelligence, Machine learning, Prenatal Screening, Median value, Maternal serum markers.
I. ĐẶT VẤN ĐỀ
Hội chứng Down, Edwards và Patau là những bất thường lệch bội nhiễm sắc thể hay gặp, với tỷ lệ gặp lần lượt là khoảng 1/700, 1/3000 và 1/6000 trẻ sinh ra, có thể dẫn đến sảy thai, thai lưu, tăng tỉ lệ tử vong sơ sinh, gây cho trẻ những bất thường về hình thái, chậm phát triển trí tuệ và giảm tuổi thọ.1 Chính vì vậy, sàng lọc và chẩn đoán sớm trước sinh là biện pháp quản lý thích hợp cho những thai nhi này. Ở Việt Nam, các phương pháp sàng lọc được sử dụng phổ biến là siêu âm thai và định lượng các marker trong huyết thanh mẹ, bao gồm double test (PAPP-A và β hCG) đối với quý 1 thai kỳ và xét nghiệm triple test (uE3, AFP và hCG) ở quý 2 thai kỳ.
Tuy nhiên, việc đánh giá các xét nghiệm này vẫn được thực hiện thủ công, phụ thuộc vào trình độ của nhân viên y tế và đòi hỏi sự kết hợp của nhiều chuyên khoa khác nhau. Để đạt được sự thống nhất giữa các cơ sở y tế, giảm tình trạng quá tải ở các bệnh viện tuyến trung ương cũng như giảm gánh nặng cho phụ nữ mang thai ở khu vực nông thôn, cần phát triển một phần mềm hỗ trợ sàng lọc sàng lọc trước sinh có thể áp dụng trong tất cả các cơ sở chăm sóc sức khỏe khác nhau. Ngày nay, trí tuệ nhân tạo (AI) được áp dụng rộng rãi trong lĩnh vực y tế.2, 3 Một số quốc gia đã phát triển thành công trong ứng dụng trí tuệ nhân tạo hỗ trợ sàng lọc trước sinh Hội chứng Down, tuy nhiên rất ít hệ thống xây dựng để sàng lọc cả 3 hội chứng.4-6
Ở Việt Nam hiện nay chưa có công bố về phần mềm AI ứng dụng trong sàng lọc trước sinh hội chứng Down, Edwards và Patau. Ngoài ra, ở Việt Nam, việc tính toán nguy cơ bất thường trước khi sinh dựa trên thuật toán dành cho người da trắng, trong khi giá trị của các dấu hiệu sinh hóa khác nhau tùy thuộc vào ví trí địa lý và chủng tộc.7 Bên cạnh đó, phẩn mềm học máy được huấn luyện trực tiếp từ dữ liệu đầu vào, vì vậy cần có bộ dữ liệu chuẩn xác để xây dựng phần mềm đạt độ chính xác cao. Đặc biệt là phải hiệu chỉnh giá trị của các dấu ấn sinh hóa phù hợp với người Việt Nam trước khi đưa dữ liệu vào phần mềm để đảm bảo việc sàng lọc có hiệu quả.
Vì vậy, chúng tôi tiến hành nghiên cứu này với hai mục tiêu:
- Xây dựng phương trình hồi quy giá trị trung vị của các dấu ấn huyết thanh trong sàng lọc trước sinh theo tuổi mẹ và cân nặng của thai phụ người Việt Nam.
- Xây dựng và đánh giá hiệu quả phần mềm trí tuệ nhân tạo trong sàng lọc trước sinh ba bất thường bẩm sinh hay gặp ở Việt Nam (Hội chứng Down, Edwards và Patau).
II. ĐỐI TƯỢNG VÀ PHƯƠNG PHÁP NGHIÊN CỨU
2.1. Đối tượng nghiên cứu
Hồ sơ bệnh án của tất cả phụ nữ mang thai đến khám và được làm xét nghiệm sàng lọc trước sinh tại Bệnh viện Phụ sản Trung ương từ tháng 1 năm 2012 đến tháng 3 năm 2022.
Để xây dựng phương trình hồi quy các giá trị trung vị của một số chất trong huyết thanh của thai phụ Việt Nam, chúng rôi đã chọn những thai phụ có kết quả xét nghiệm double test và triple test nguy cơ thấp, kết quả nhiễm sắc thể của thai nhi bình thường, thai đơn, thai tự nhiên, thai còn sống và bệnh án thai phụ phải đầy đủ thông tin. Chúng tôi loại trừ những trường hợp đa thai, thụ tinh ống nghiệm, mẹ mắc đái tháo đường hoặc hút thuốc lá. Có 5446 trường hợp xét nghiệm double test và 3247 trường hợp triple test đáp ứng đủ tiêu chuẩn lựa chọn và tiêu chuẩn loại trừ.
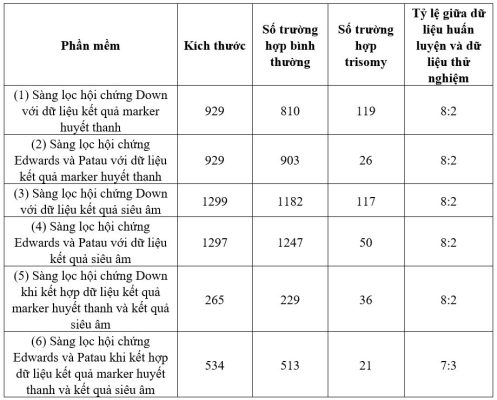
Để xây dựng phần mềm AI, chúng tôi lựa chọn cả những trường hợp bình thường và những trường hợp thai nhi được chẩn đoán trisomy 21, trisomy 18 và trisomy 13. Tất cả các trường hợp phải có đầy đủ thông tin hồ sơ bệnh án. Sau khi loại bỏ các trường hợp không đáp ứng tiêu chí lựa chọn, tập dữ liệu thu được được chia thành 2 nhóm: dữ liệu huấn luyện và dữ liệu thử nghiệm. Kích thước và tỷ lệ của hai nhóm dữ liệu được hiển thị trong Bảng 1:
Bảng 1. Kích thước và tỷ lệ của dữ liệu training và dữ liệu testing sử dụng trong phần mềm
2.2. Phương pháp nghiên cứu
Nghiên cứu phân tích tổng hợp, mô tả hồi cứu và tiến cứu dữ liệu.
Thời gian nghiên cứu: 11/2020 – 5/2022
Để xây dựng phương trình hồi quy giá trị trung vị cho các marker sinh hóa của thai phụ Việt Nam, chúng tôi đã loại bỏ các giá trị ngoại lai. Dữ liệu thu được chia thành các nhóm dựa trên tuổi thai và cân nặng của mẹ. Sử dụng phần mềm Stata 13.0 và SPSS 20.0 để khảo sát mối tương quan giữa giá trị trung vị của các marker sinh hóa và tuổi thai (tính theo ngày). Sau đó, chúng tôi khảo sát các mô hình hồi quy khác nhau và chọn mô hình phù hợp nhất với giá trị R2 lớn nhất. Giá trị MoM (Multiples of median) được xác định bởi công thức: MoM= Giá trị định lượng/Median
Sau đó, các giá trị MoM được hiệu chỉnh theo cân nặng của mẹ.
Để xây dựng phần mềm trí tuệ nhân tạo, trước tiên, chúng tôi đã khảo sát trên 4 mô hình: Random Forest, the K-Nearest Neighbors (KNN), Support Vector Machine (SVM), and XGBoost (Extreme Gradient Boosting) trên tập dữ liệu training. Các đặc điểm được sử dụng để huấn luyện mô hình bao gồm: tuổi mẹ, tuổi thai, tiền sử sinh con mắc hội chứng Down, các chỉ số sinh hóa (MoM free-β hCG, MoM PAPP-A, MoM uE3, MoM AFP, và MoM hCG) và kết quả siêu âm của thai gồm 12 chỉ số trong siêu âm (độ mờ da gáy, đường kính lưỡng đỉnh, chu vi đầu, đường kính tiểu não, chiều dài xương mũi, đường kính ngang bụng, chu vi bụng, hai thận, dấu hiệu bàn tay mở, chiều dài xương đùi, nhau thai và nước ối). Bởi vì số lượng thai bất thường ít hơn nhiều so với số lượng thai bình thường, nên chúng tôi đã sử dụng thuật toán SMOTE để tăng cường dữ liệu bằng cách tạo các điểm dữ liệu tổng hợp dựa trên các điểm dữ liệu thô. Sau đó bốn mô hình được thử nghiệm trên tập dữ liệu thử nghiệm để đánh giá hiệu quả và chọn mô hình có độ chính xác cao nhất. Thuật toán tăng dữ liệu không được sử dụng trên tập dữ liệu thử nghiệm để đảm bảo phân bố dữ liệu.
Đạo đức nghiên cứu
– Nghiên cứu đã được thông qua bởi Hội đồng Đạo đức của Bệnh viện Phụ sản Trung Ương theo văn bản số 1776/QĐ-PSTW ngày 29/12/2020.
– Mọi thông tin cá nhân, bệnh án của thai phụ đều được bảo mật. Tất cả các thông tin chỉ được sử dụng cho mục đích nghiên cứu.
III. KẾT QUẢ NGHIÊN CỨU
2.4. Phương trình hồi quy các giá trị trung vị marker huyết thanh của thai phụ Việt Nam trong sàng lọc trước sinh
2.4.1. Phương trình hồi quy giữa giá trị trung vị của các marker huyết thanh với tuổi thai
Giá trị trung vị của các marker sinh hóa được phân chia theo ngày thai, và trung vị của mỗi nhóm sẽ được điều chỉnh theo cân nặng. Các giá trị trung vị của marker sinh hóa được mô tả bởi mô hình Linear, Quadratic, Logarithmic-quadratic và Cubic. Việc lựa chọn mô hình phù hợp nhất dựa trên giá trị R2.
𝑀𝑒𝑑𝑖𝑎𝑛 𝑓𝑟𝑒𝑒 − 𝛽h( 𝑛𝑔/𝑚𝐿) = −0.1077𝑥2 − 20.853𝑥 + 1059.417; R2 = 0.801
𝑀𝑒𝑑𝑖𝑎𝑛 𝑃𝐴𝑃𝑃 − (𝑛𝑔/𝑚𝐿) = 4.476𝑥2 − 715.888𝑥 + 31621.34; R2 = 0.769
log 𝑀𝑒𝑑𝑖𝑎𝑛 𝑢𝐸3(𝑛𝑚𝑜𝑙/𝐿) = −0.0009424 𝑥2 + 0.2328735𝑥 − 13.93196; R2 = 0.852
𝑀𝑒𝑑𝑖𝑎𝑛 (𝑈/𝑚𝐿) = −0.0278465𝑥2 + 7.215828𝑥 − 423.2132; R2 = 0.534.
𝑀𝑒𝑑𝑖𝑎𝑛 h(𝑈/𝐿) = 56.59625𝑥2 − 14377.2𝑥 + 943074.1; R2 = 0.782.
Với 𝑥: Tuổi thai (theo ngày)
Các phương trình hồi quy tuyến tính thu được đều có R2 lớn hơn 0.5, cho thấy các mô hình đều khá phù hợp.
2.4.2. Phương trình hiệu chỉnh MoM theo cân nặng của mẹ
Các phương trình hồi quy thu được đều có R2 lớn hơn 0.5, cho thấy mô hình khá phù hợp. Trong đó, phương trình hồi quy giữa CorrMoM PAPP-A và cân nặng của mẹ là phương trình có R2 cao nhất (R2 = 0,975) (chi tiết phương trình xin xem thêm bản full pdf bên dưới kèm theo)
2.5. Mô hình học máy trong sàng lọc trước sinh hội chứng Down, Edwards và Patau
Bảng 2. Độ chính xác của mô hình học máy với bộ dữ liệu kết quả sàng lọc sinh hóa mẹ
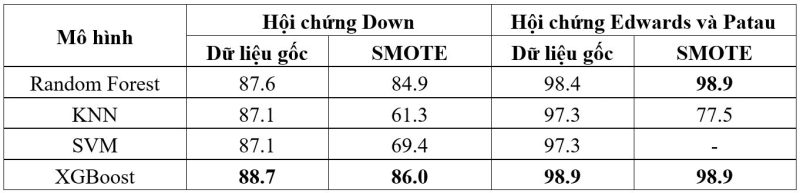
Khi sử dụng bộ dữ liệu kết quả huyết thanh của mẹ để huấn luyện, mô hình XGBoost cho độ chính xác cao nhất đối với cả ba hội chứng và phương pháp tăng dữ liệu không cải thiện hiệu quả của các mô hình này.
Bảng 3. Độ chính xác của mô hình học máy với bộ dữ liệu về kết quả siêu âm thai
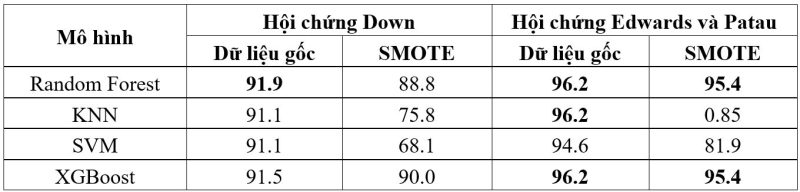
Với bộ dữ liệu kết quả siêu âm thai, mô hình Random Forest mang lại hiệu quả cao nhất cho việc sàng lọc hội chứng Down. Đối với hội chứng Edwards và Patau, mô hình Random Forest và XGBoost cho kết quả tương tự.
Bảng 4. Độ chính xác của mô hình học máy khi kết hợp bộ dữ liệu về kết quả sàng lọc sinh hóa mẹ và kết quả siêu âm thai
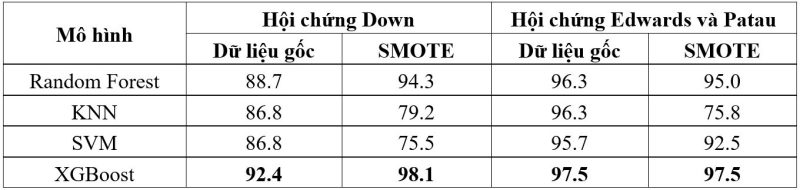
Khi huấn luyện mô hình học máy bằng cách kết hợp kết quả sàng lọc sinh hóa máu mẹ và kết quả siêu âm thai, mô hình XGBoost có độ chính xác cao nhất đế sàng lọc cả 3 hội chứng. Thuật toán SMOTE đã cải thiện độ chính xác của mô hình sàng lọc hội chứng Down.
2.5.2. Phẩn mềm trí tuệ nhân tạo online dựa trên mô hình XGBoost
Hình 1. Một vài cơ sở dữ liệu để xây dựng phần mềm học máy
Chúng tôi đã xây dựng một phần mềm trên nền tảng trực tuyến để nhập dữ liệu hồ sơ bệnh án như trong Hình 1. Cơ sở dữ liệu này sẽ được cập nhật liên tục để nâng cao hiệu quả của mô hình
Hình 2. Giao diện dự báo nguy cơ của phần mềm
Chúng tôi đã xây dựng một phần mềm dự báo nguy cơ trên nền tảng trực tuyến như trong Hình 2. Phần mềm sẽ dự báo thai nguy cơ cao hay thấp mắc các bất thường, góp phần hỗ trợ bác sỹ lâm sàng trong việc ra quyết định
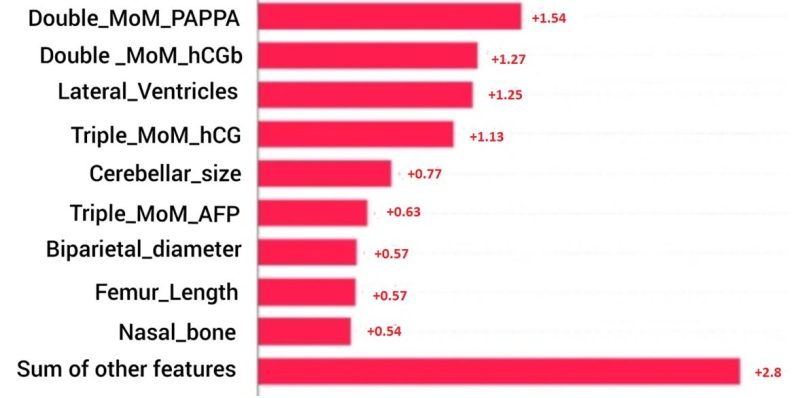
Hình 3. Tỷ lệ đóng góp của từng đặc điểm trong xác định nguy cơ cao hay thấp mang bất thường của phần mềm
Sau quá trình học máy, phần mềm AI đã tổng hợp tỷ lệ đóng góp của từng đặc điểm trong tính nguy cơ trong thai kỳ. Theo Hình 3, giá trị MoM của nồng độ PAPP-A là quan trọng nhất. Tỷ lệ đóng góp thay đổi theo thời gian học máy. Đây là cơ sở để AI đưa ra nguy cơ chính xác hơn trong sàng lọc trước sinh hội chứng Down, Edwards và Patau.
IV. BÀN LUẬN
4.1. Các phương trình hồi qui cho các giá trị trung vị của các marker sinh hóa máu mẹ trong sàng lọc trước sinh hiệu chỉnh theo tuổi thai và cân nặng mẹ dành riêng cho người Việt Nam
Việc tính toán giá trị trung vị của một số chỉ số hóa sinh là bước đầu tiên trong việc tính toán nguy cơ thai mang bất thường bẩm sinh. Giá trị này sẽ thay đổi và có tính đặc trưng riêng cho từng khu vực, chủng tộc, dân tộc.
Trong nghiên cứu này, phương trình biểu diễn free β-hCG và PAPP-A đều là các phương trình bậc 2 tương tự như nghiên cứu của Thái Lan tiến hành tại Chiang Mai trên 2339 thai phụ có thai kì bình thường,8 trong khi nghiên cứu tiến hành trên 943 thai phụ thuộc dân tộc thiểu số người Trung Quốc là phương trình bậc 3 đối với PAPP-A và phương trình hàm mũ đối với free beta-hCG9. Theo như các nghiên cứu này, nếu không có sự điều chỉnh trung vị về mặt chủng tộc, nguy cơ của mỗi đối tượng sẽ bị đánh giá thấp hơn từ 5.9% xuống còn 5.3% trong nghiên cứu của Trung Quốc và từ 5.1% xuống 4.9% trong nghiên cứu của Thái Lan, dẫn đến làm giảm độ nhạy cũng như khả năng phát hiện hội chứng Down.
Đối với xét nghiệm triple test, một số quốc gia đã tiến hành nghiên cứu và đưa ra mô hình dự báo cho riêng họ, như nghiên cứu của Đài Loan năm 2020 với số lượng dữ liệu lớn đã đưa ra mô hình hồi qui tuyến tính giữa giá trị trung vị của uE3, AFP, hCG và phương trình hiệu chỉnh MoM của các chỉ số sinh hóa này theo cân nặng của mẹ dưới dạng f(x)= P1×X2 +P2×X+P3 hoặc f(x)= P1×X +P2,
Nghiên cứu của chúng tôi cho kết quả giá trị trung vị của các chỉ số hóa sinh uE3, AFP, hCG theo từng ngày tuổi thai cũng biến thiên theo xu hướng tương tự như vậy.
Chỉ số R2 trong mô hình hồi quy tuyến tính phản ánh mức độ giải thích của các biến độc lập đối với biến phụ thuộc, cụ thể là giữa tuổi thai theo ngày và các marker sinh hóa, biến thiên trong khoảng từ 0 đến 1. R2 càng gần về 1 thì mô hình càng phù hợp và có ý nghĩa. Ở nghiên cứu này, đối với xét nghiệm double test, giá trị R2 của phương trình dự đoán trung vị free-beta hCG là 0,801 và của PAPP-A là 0,769; còn đối với xét nghiệm triple test, R2 của phương trình dự đoán trung vị của uE3, AFP và hCG lần lượt là 0,852; 0,534 và 0,782 cho thấy sự phù hợp của mô hình là tương đối cao.
4.2. Các mô hình học máy hỗ trợ sàng lọc trước sinh hội chứng Down, Edwards, Patau
Trên thế giới, trí tuệ nhân tạo, đặc biệt là mô hình học máy đã được nhiều tác giả nghiên cứu ứng dụng trong việc sàng lọc trước sinh và thu được hiệu quả cao. Nghiên cứu năm 2015 của Andreas C. Neocleous và cộng sự tiến hành huấn luyện các mô hình mạng nơ-ron nhân tạo, K-NN và SVM trên bộ cơ sở dữ liệu gồm 51,208 trường hợp thai đơn được làm sàng lọc trước sinh trong quí I thai kỳ.11 Trong đó, các tác giả đã sử dụng các đặc trưng bao gồm: tuổi mẹ, tiền sử sinh con mắc hội chứng Down, CRL, MoM free β-hCG, MoM PAPP-A, NT, Nasal bone, tricuspid flow và ductus venosus flow. Kết quả đạt được là mạng neuron nhân tạo cho hiệu quả cao nhất với tỉ lệ phát hiện hội chứng Down là 100% với tỉ lệ âm tính giả 0% và đối với các thể lệch bội nhiễm sắc thể khác (T13,T18,Turner, tam bội) tỉ lệ phát hiện lên đến 96.1%, tỉ lệ dương tính giả là 3.9%.11
Năm 2017, Li và các cộng sự đề xuất một framework học máy xếp tầng được thiết kế để dự đoán hội chứng Down dựa trên ba giai đoạn bổ sung: 1) phán đoán trước với kỹ thuật rừng cách ly, 2) kết hợp nhiều mô hình theo chiến lược bỏ phiếu và 3) phán đoán cuối cùng bằng phương pháp hồi quy logistic.12 Mô hình được huấn luyện trên bộ cơ sở dữ liệu gồm 100,244 thai bình thường và 108 thai bất thường. Kết quả thử nghiệm cho thấy sự kết hợp các đặc trưng đầu vào để sàng lọc Down được đề xuất tốt nhất là nhóm alpha-fetoprotein (AFP), human chorionic gonadotropin (hCG), unconjugated estriol (uE3), tuổi mẹ với tỉ lệ dương tính thật 95% và tỉ lệ dương tính giả 4%.12
Trong nghiên cứu này, chúng tôi đã xây dựng các mô hình học máy trong sàng lọc trước sinh các hội chứng Down, Edwards và Patau. Vì giá trị của các marker sinh hóa máu mẹ trong hội chứng Down thay đổi khác so với thai mang hội chứng Edwards và Patau nên với mỗi tập dữ liệu, chúng tôi xây dựng mô hình riêng cho hội chứng Down và một mô hình khác cho hội chứng Edwards và Patau. Trên thực tế, bộ dữ liệu chúng tôi sử dụng nhỏ hơn so với các nghiên cứu khác. Khi sử dụng thuật toán SMOTE để tăng dữ liệu, độ chinh xác của các mô hình có xu hướng tăng lên. Tuy nhiên, dữ liệu này có thể làm thay đổi phân bố dữ liệu so với dữ liệu ban đầu. Khi huấn luyện với bộ dữ liệu kết hợp kết quả siêu âm thai và sinh hóa máu mẹ, các mô hình học máy đã cho ra kết quả có độ chính xác cao. Điều này cho thấy càng sử dụng nhiều yếu tố để huấn luyện thì độ chính xác thu được càng cao. Đây là một trong những điểm mạnh của nghiên cứu này.
Tất cả các mô hình đều đạt được độ chính xác cao. Chúng tôi lựa chọn mô hình XGBoost với độ chính xác cao nhất để phát triển phần mềm AI online hỗ trợ sàng lọc trước sinh các hội chứng Down, Edwards và Patau ở Việt Nam. Phần mềm có giao diện thân thiện với người dùng, dễ dàng áp dụng tại tất cả các cơ sở y tế trên cả nước. Hơn thế nữa, sau khi đưa vào sử dụng, độ chính xác của mô hình sẽ ngày càng tăng nhờ việc tiếp tục được bổ sung dữ liệu cho huấn luyện.
V. KẾT LUẬN
Nghiên cứu của chúng tôi đã đưa ra các phương trình hồi qui tuyến tính cho các giá trị trung vị của các marker sinh hóa máu mẹ trong sàng lọc trước sinh hiệu chỉnh theo tuổi thai và cân nặng mẹ. Giá trị R2 của các mô hình này khá cao cho thấy chúng phù hợp với thai phụ người Việt Nam. Đây là bước đầu tiên trong việc tính toán nguy cơ trong sàng lọc trước sinh cho người Việt Nam.
Chúng tôi đã xây dựng và thử nghiệm thành công mô hình học máy dưới dạng phần mềm online hỗ trợ sàng lọc trươc sinh cho hội chứng Down, Edwards và Patau ở Việt Nam. Mô hình XGBoost có độ chính xác cao nhất.
Lời cảm ơn: Nhóm tác giả xin chân thành cảm ơn Ban Giám đốc và các đồng nghiệp tại Bệnh viện Phụ sản TW. Nghiên cứu này thuộc đề tài cấp Nhà nước : “Ứng dụng trí tuệ nhân tạo trong sàng lọc trước sinh một số bất thường hay gặp tại Việt Nam” thuộc phương trình KC 4.0-19/25.
TÀI LIỆU THAM KHẢO
- Screening for Fetal Chromosomal Abnormalities: ACOG Practice Bulletin Summary, Number 226. 2020;(1873-233X (Electronic))
- Amisha, Malik P, Pathania M, Rathaur VK. Overview of artificial intelligence in medicine. 2019;(2249-4863 (Print))
- Davenport T, Kalakota R. The potential for artificial intelligence in healthcare. 2019;(2514-6645 (Print))
- Sun YA-O, Zhang L, Dong D, et al. Application of an individualized nomogram in first-trimester screening for trisomy 21. 2021;(1469-0705 (Electronic))
- Zhang HG, Jiang YT, Dai SD, Li L, Hu XN, Liu RZ. Application of intelligent algorithms in Down syndrome screening during second trimester pregnancy. 2021;(2307-8960 (Print))
- Neocleous AA-O, Syngelaki AA-O, Nicolaides KH, Schizas CN. Two-stage approach for risk estimation of fetal trisomy 21 and other aneuploidies using computational intelligence systems. 2018;(1469-0705 (Electronic))
- Vranken G, Reynolds T Fau – Van Nueten J, Van Nueten J. Medians for second-trimester maternal serum markers: geographical differences and variation caused by median multiples-of-median equations. 2006; (0021-9746 (Print))
- Luewan S, Sirichotiyakul S Fau – Yanase Y, Yanase Y Fau – Traisrisilp K, Traisrisilp K Fau – Tongsong T, Tongsong T. Median levels of serum biomarkers of fetal Down syndrome detected during the first trimester among pregnant Thai women. 2012;(1879-3479 (Electronic))
- Leung TY, Spencer K, Leung TN, Fung TY, Lau TK. Higher median levels of free beta-hCG and PAPP-A in the first trimester of pregnancy in a Chinese ethnic group. Implication for first trimester combined screening for Down’s syndrome in the Chinese population. Fetal diagnosis and therapy. 2006;21(1):140-3.
- Hu ZM, Luo LL, Li L, Dai SD, Zhang HG, Liu RZ. Indigenization of the median of markers for Down syndrome screening based on statistical analysis of medical big data. (1875-6263 (Electronic))
- Neocleous Ac Fau – Nicolaides KH, Nicolaides Kh Fau – Schizas CN, Schizas CN. First Trimester Noninvasive Prenatal Diagnosis: A Computational Intelligence Approach. 2016;(2168-2208 (Electronic))
- Ling Li WL, Hongguo Zhang, Yuting Jiang, Xiaonan Hu, Ruizhi Liu. Down Syndrome Prediction Using a Cascaded Machine Learning Framework Designed for Imbalanced and Feature-correlated Data. IEEEAcess. 2017;
( Nguồn: Số 518, tháng 9/2022, Tạp chí Y Học Việt Nam, trang 154-164, link full tạp chí: ![]() )
)